Reverse engineering early language acquisition
One of the most fascinating facts about human infants concerns the speed at which they acquire their native(s) language(s). During the first year alone, infants achieve impressive landmarks regarding three key language components (see Figure 1). First, they tune into the phonemic categories (consonants and vowels) of their language, i.e., they lose the ability to distinguish some fine phonetic contrasts that belong to the same category, enhance their ability to distinguish some between-category contrasts, and refine their ability to ignore acoustic variations due to speaker characteristics. Second, infants refine their ability to segment the speech stream, from large prosodic units to small ones, and determine the suprasegmental features that are relevant for word recognition. Third, infants start to extract very frequent word patterns from their environnment, and compile segmentation strategies that help them constructing a recognition lexicon.
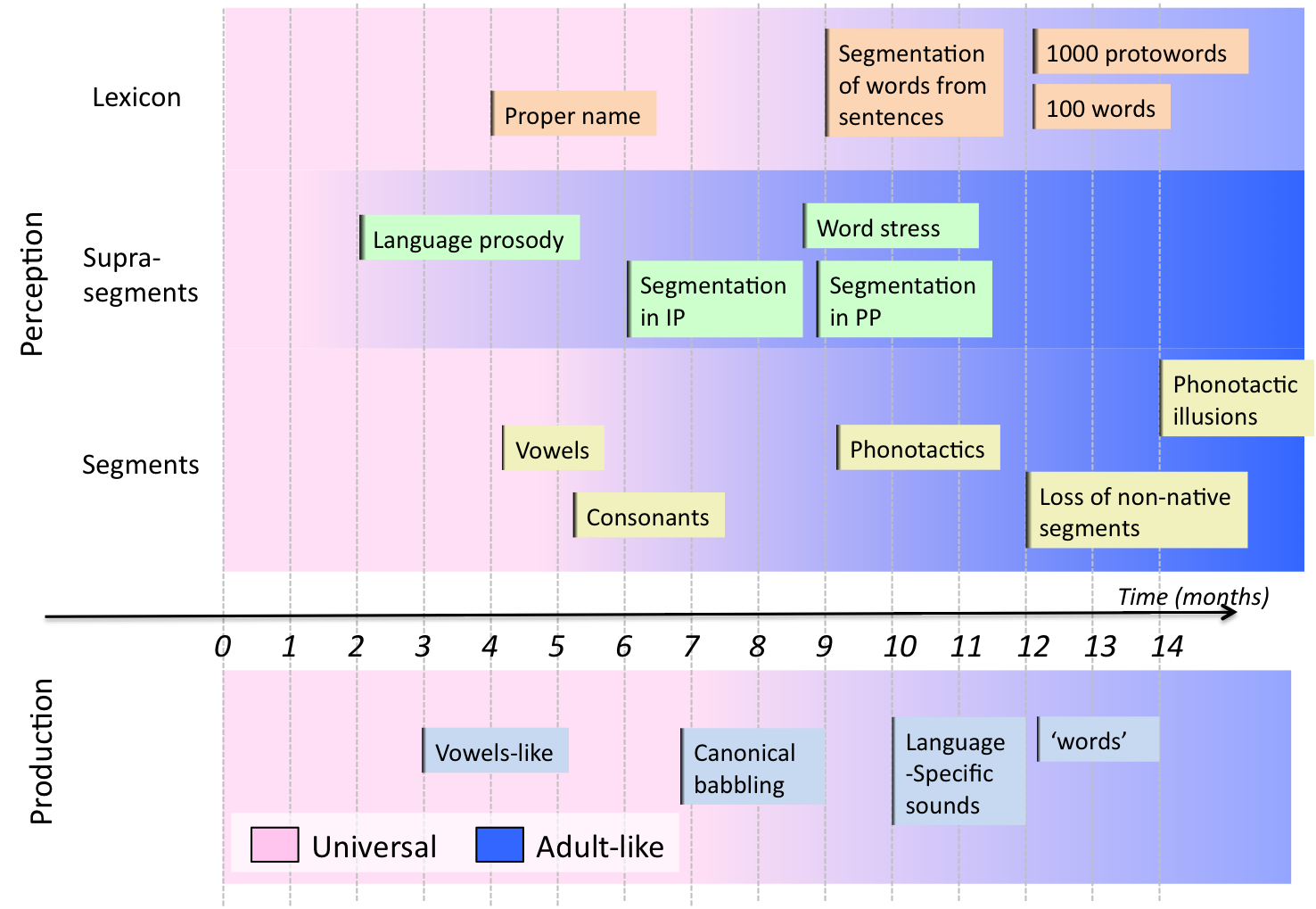
Figure 1. Time line of early language development across different domains of speech perception and production. Adapted from Kuhl et al. (2004).
Three things are important to note: during the first year of life, and before they can correctly articulate the sounds of their language, infants acquire efforlessly several aspects of language that are extremely difficult for adults to learn later in life: the inventory of segments and suprasegments, as well as language-specific word segmentation strategies. Second, they do this without direct parental supervision. Finally, and most suprisingly, the acquisition of these three components is not done sequentially, but in a largely overlapping fashion.
Surprisingly, little is known about the computational and cognitive mechanisms making it possible. Modeling approches have used advances in Automatic Speech Recognition (ASR), Machine Learning (ML) and Computational Linguistics (CL) to propose to construct phonemic categories through unsupervised clustering (Vallabha et al, 2007), to perform word segmentation through distributional learning (Brent 1999), or to learn phonological rules through grammar induction (Tesar & Smolensky, 1998). Up to now, however, most modeling approaches have been rather limited, focusing on one subproblem in isolation, and/or on very simplified input (toy languages, selected parameters, etc.), leaving open the scalability of these models when confronted with real-life corpora of spontaneous speech.
The Challenge
Constructing a full model for the early acquisition of language is a formidable challenge for two reasons: variability and interdependance. Regarding variability, speech sound are not to be found in the acoustic waveform as a sequence of isolated discrete units. Rather, a long pipeline of phonological and phonetic processes transform the string of abstract phonemes and words into a parallel stream of overlapping gestures, which are converted into sounds through non-linear acoustic processes which depend on talker characteristics (see Figure 2).
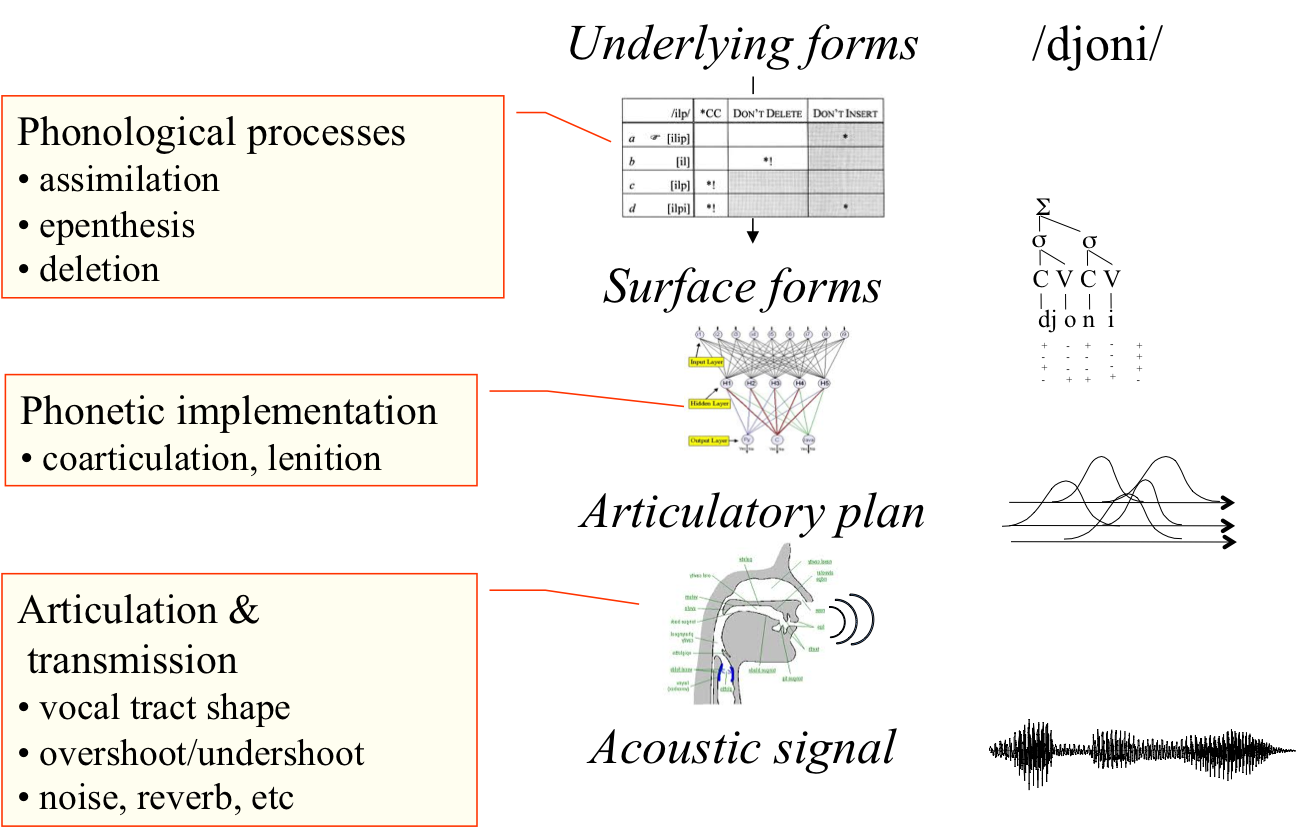
Figure2. Sources of variability for speech sounds
As a result, there is a stricking lack of one-to-one correspondance between observable acoustic elements and underlying linguistic units. The task of the infant is to inverse the pipeline of phonological, phonetic and acoustic processes, without knowing what the parameters of these processes are. Regarding interdependance, the different learning sub-problems can not be considered separately. For instance, unsupervised clustering algorithms typically use as input a small number of hand-picked phonetic parameters: mean formant frequency, phoneme duration, etc. This presupposes that infants know how to segment the continuous stream into discrete entities like consonants or vowels, and which cues are relevant; this is problematic given that segmentation and cue selection are not universal but depend on the phonological rules of the language. Likewise, word segmentation algorithms presuppose that speech is represented in terms of discrete phonemes or syllables, which themselves depend on phonological rules. However, computational models of phonological rule induction work under the assumption that word forms are available, and therefore depend on the previous two components. These logical dependencies naturally lead to a bootstrapping paradox.
Subprojects
The overarching aim is to construct a complete computational model and link it to specific brain structures (see Figure 3). To reach this goal, we investigate key issues in subprojects carried out in the group or with collaborators. These subprojects use a variety of machine learning techniques on large databases of real speech corpora (400h of spontaneous Japanese and Dutch), and carry out empirical tests in human infants (0-12 months) using behavioral (eye movement) or imaging techniques (high density EEGs, functional Near InfraRed Spectroscopy).
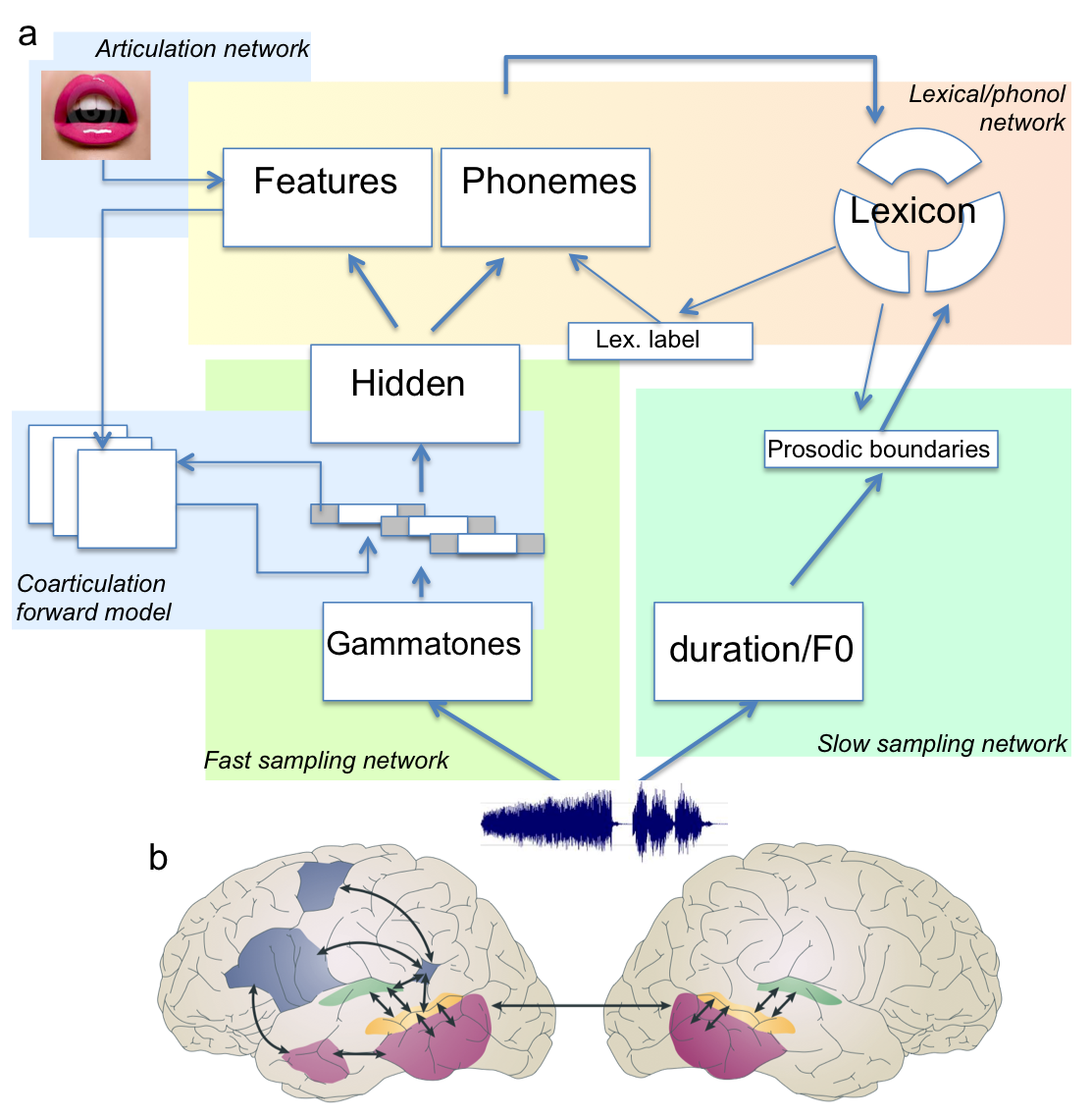
Figure 3. Tentative architecture for a model of early language acquisition. b. Candidate brain regions for the implementation of the model (from Hickock & Poeppel, 2007).
Speech coding
Automatically discovering linguistic units like phonemes from speech is difficult, in part because speech is customarily represented in terms of local feature vectors (e.g. Cepstral coefficients or auditory features computed over a 15-25 ms window). Clusters built over this kinds of features will necessarily correspond to rather local spectro-temporal events. But phonemes are produced as overlapping articulatory trajectories spanning between 50 and 150ms, and end up being represented as sequences of such clusters. The aim of this subproject is to sidestep the problem of this mismatch by replacing fine-grained feature codes by coarse- grained ones that span a larger fragment of the speech signal. We are currently using sparse dictionnaries and deep belief networks (Hinton, 2007) to derive such features.
Acquiring a protolexicon
Traditionally, in linguistics, phonemes are defined in terms of minimal pairs: /r/ and /l/ are two distinct phonemes in English because “right” and “light” mean different things. No such pair exists in Japanese, hence, Japanese does not have the contrast between /r/ and /l/. This could be helpful for discovering phonetic categories. However, it seems that infants don’t understand enough words (around 100 words at the end of the first year) to make such a strategy possible, since minimal pairs are quite uncommon in most languages. However, most researchers have overlooked the possibility that infants might recognize a large number of familiar word forms before they know what these words mean. The aim of this subproject is to explore how a rudimentary ‘protolexicon’ could be constructed by the young infant (through unsupervized spoken term discovery, Brent, 1999), which could help him learning phonological structures, even though this protolexicon contains many errors.
Other subprojects
As the team grows, we will develop subprojects in some of the following areas: the inverse modeling of co-articulation, unsupervized talker normalization, the discovery of prosodic structure (prosodic boundaries and prosodic features), the discovery of phonological classes or features, the role of child-parent interactions, the detection and modeling of dialectal/sociolectal variations, the potential role of rudimentary semantic information, the extraction of function words, and the interactions between all of these levels. We are also interested in the emergence of brain specialization for language in early infancy as well as the brain correlates of the computational mechanisms for language acquisition.
Tools
The modeling part of this project rests on:
-
automatic speech recognition (Hidden Markov Models, see Jelinek, 1998; zero ressource speech technologies, e.g. Park & Glass, 2008),
-
machine learning techniques (clustering, structure discovering, deep belief networks, sparse coding, e.g. Hoyer, 2003, Mohamed et al, 2012),
-
signal processing (modeling of auditory processing in the brain, e.g. Smith & Lewicky, 2006, Pasley et al 2012),
-
Bayesian models (adaptor grammars, see Johnson & Demuth, 2010: Goldwater et al, 2009).
The Experimental part of this project rests on:
-
eye tracking techniques in infants (see Aslin, 2012),
-
EEGs (eg, Dehaene-Lambertz & Gliga, 2004),
-
fonctional Near InfraRed Spectroscpy, fNIRS (see Minagawa-Kawai, et al 2008; Gervain et al, 2011).
References
Aslin, R. N. (2012). Infant eyes: A window on cognitive development. Infancy, 17, 126-140.
Brent, M. R. (1999). Speech segmentation and word discovery: A computational perspective. TICS, 3, 294-300.
Dehaene-Lambertz, G. & Gliga, T. (2004). Common neural basis for phoneme processing in infants and adults. Journal of Cognitive Neuroscience, 16:1375-87.
Gervain, J., Mehler, J., Werker, J. F., Nelson, C. A., Csibra, G., Lloyd-Fox, S., Shukla, M., and Aslin, R. N. (2011). Near-Infrared Spectroscopy: A Report from the McDonnell Infant Methodology Consortium. Developmental Cognitive Neuroscience, 1, 22-46.
Goldwater, S., Griffiths, T. & Johnson, M. (2009). A Bayesian Framework for Word Segmentation: Exploring the Effects of Context, Cognition 112:1, pp. 21-54.
Hickok, G. & Poeppel, D. (2007). The cortical organization of speech processing. Nat. Rev. Neuroscience 8, 393-402.
Hinton, G.E., (2007). Learning multiple layers of representation. Trends in Cognitive Science, 11(10) :428-434.
Hoyer, P.O. (2003). Modeling receptive fields with non-negative sparse coding. Neurocomputing, 52-54, 547-552.
Jelinek, F. (1998). Statistical Methods of Speech Recognition. Cambridge, Mass: MIT Press.
Johnson, M. & Demuth, K. (2010). Unsupervised phonemic Chinese word segmentation using Adaptor Grammars, Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), pp. 528-536.
Kuhl, P. K. (2004). Early language acquisition: cracking the speech code. Nature Reviews Neuroscience, 5, 831-843.
Minagawa-Kawai, Y., Mori, K., Hebden, J.C., Dupoux, E., (2008). Optical imaging of infants’ neurocognitive development: recent advances and perspectives. Dev Neurobiol 68, 712-728.
Mohamed, A., Dahl, G. E. and Hinton, G. E. (2012). Acoustic Modeling using Deep Belief Networks. IEEE Trans. on Audio, Speech, and Language Processing.
Park, A. and Glass, J. R. (2008). Unsupervised pattern discovery in speech, IEEE T-ASLP, 16(1), pp. 186-197.
Pasley, B.N., David, S.V., Mesgarani, N., Flinker, A., Shamma, S.A, et al. (2012). Reconstructing Speech from Human Auditory Cortex. PLoS Biol 10(1): e1001251.
Vallabha, G. K., McClelland, J. L., Pons, F., Werker, J. & Amano, S. (2007) Unsupervised learning of vowel categories from infant-directed speech, PNAS, 104:33, 13273-13278.
Smith, E. & Lewicki, M. S. (2006). Efficient Auditory Coding, Nature, 439, 978-982.
Tesar, B., & Smolensky, P. (1998). Learnability in Optimality Theory. Linguistic Inquiry 29; 229-268.