Reverse engineering early language acquisition
L’un des faits les plus fascinants concernant les nourrissons humains porte sur la vitesse à laquelle ils acquièrent leur(s) langue(s) maternelle(s). Au cours de la première année seulement, les nourrissons atteignent des jalons impressionnants concernant trois composantes clés du langage (voir Figure 1). Premièrement, ils s’ajustent aux catégories phonémiques (consonnes et voyelles) de leur langue, c’est-à-dire qu’ils perdent la capacité de distinguer certains contrastes phonétiques fins qui appartiennent à la même catégorie, améliorent leur capacité à distinguer certains contrastes entre catégories, et affinent leur capacité à ignorer les variations acoustiques dues aux caractéristiques des locuteurs. Deuxièmement, les nourrissons affinent leur capacité à segmenter le flux de parole, des grandes unités prosodiques aux petites, et déterminent les caractéristiques suprasegmentales qui sont pertinentes pour la reconnaissance des mots. Troisièmement, les nourrissons commencent à extraire des schémas de mots très fréquents de leur environnement, et élaborent des stratégies de segmentation qui les aident à construire un lexique de reconnaissance.
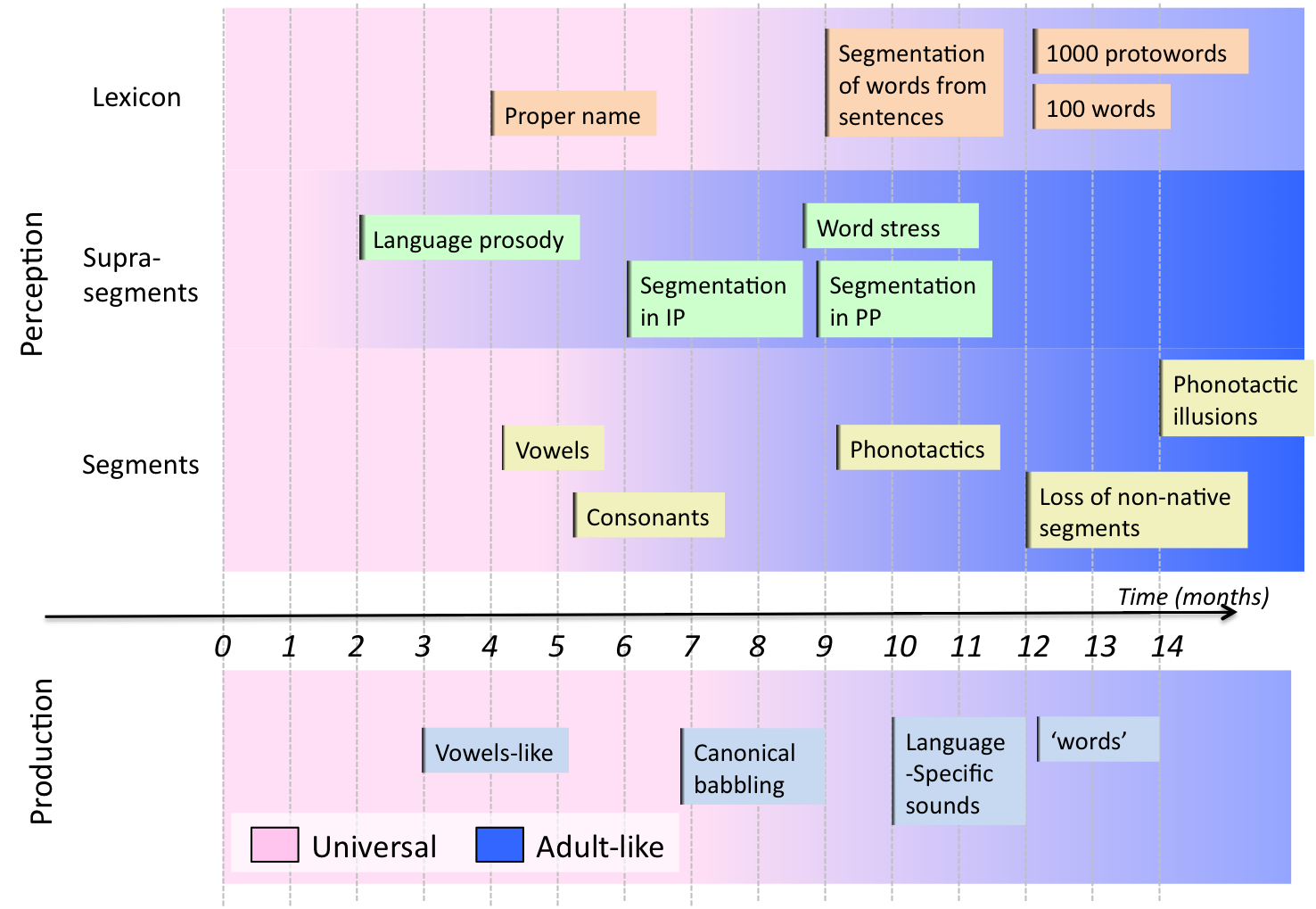
Figure 1. Time line of early language development across different domains of speech perception and production. Adapted from Kuhl et al. (2004).
Trois choses sont importantes à noter : pendant la première année de vie, et avant de pouvoir articuler correctement les sons de leur langue, les nourrissons acquièrent sans effort plusieurs aspects du langage qui sont extrêmement difficiles à apprendre pour les adultes plus tard dans la vie : l’inventaire des segments et suprasegments, ainsi que les stratégies de segmentation des mots spécifiques à chaque langue. Deuxièmement, ils font cela sans supervision parentale directe. Enfin, et de façon plus surprenante, l’acquisition de ces trois composantes ne se fait pas de manière séquentielle, mais de façon largement superposée.
De manière surprenante, on sait peu de choses sur les mécanismes computationnels et cognitifs qui rendent cela possible. Les approches de modélisation ont utilisé les avancées en Reconnaissance Automatique de la Parole (RAP), Apprentissage Automatique (AA) et Linguistique Computationnelle (LC) pour proposer de construire des catégories phonémiques par regroupement non supervisé (Vallabha et al, 2007), d’effectuer la segmentation des mots par apprentissage distributional (Brent 1999), ou d’apprendre des règles phonologiques par induction grammaticale (Tesar & Smolensky, 1998). Jusqu’à présent, cependant, la plupart des approches de modélisation ont été plutôt limitées, se concentrant sur un sous-problème isolé, et/ou sur des données d’entrée très simplifiées (langages jouets, paramètres sélectionnés, etc.), laissant ouverte la question de la passage à l’échelle de ces modèles lorsqu’ils sont confrontés à des corpus réels de parole spontanée.
Le Challenge
Construire un modèle complet pour l’acquisition précoce du langage représente un défi formidable pour deux raisons : la variabilité et l'interdépendance. Concernant la variabilité, les sons de la parole ne se trouvent pas dans la forme d’onde acoustique sous forme de séquence d’unités discrètes isolées. Au contraire, une longue chaîne de processus phonologiques et phonétiques transforme la chaîne de phonèmes et de mots abstraits en un flux parallèle de gestes superposés, qui sont convertis en sons par des processus acoustiques non linéaires qui dépendent des caractéristiques du locuteur (voir Figure 2).
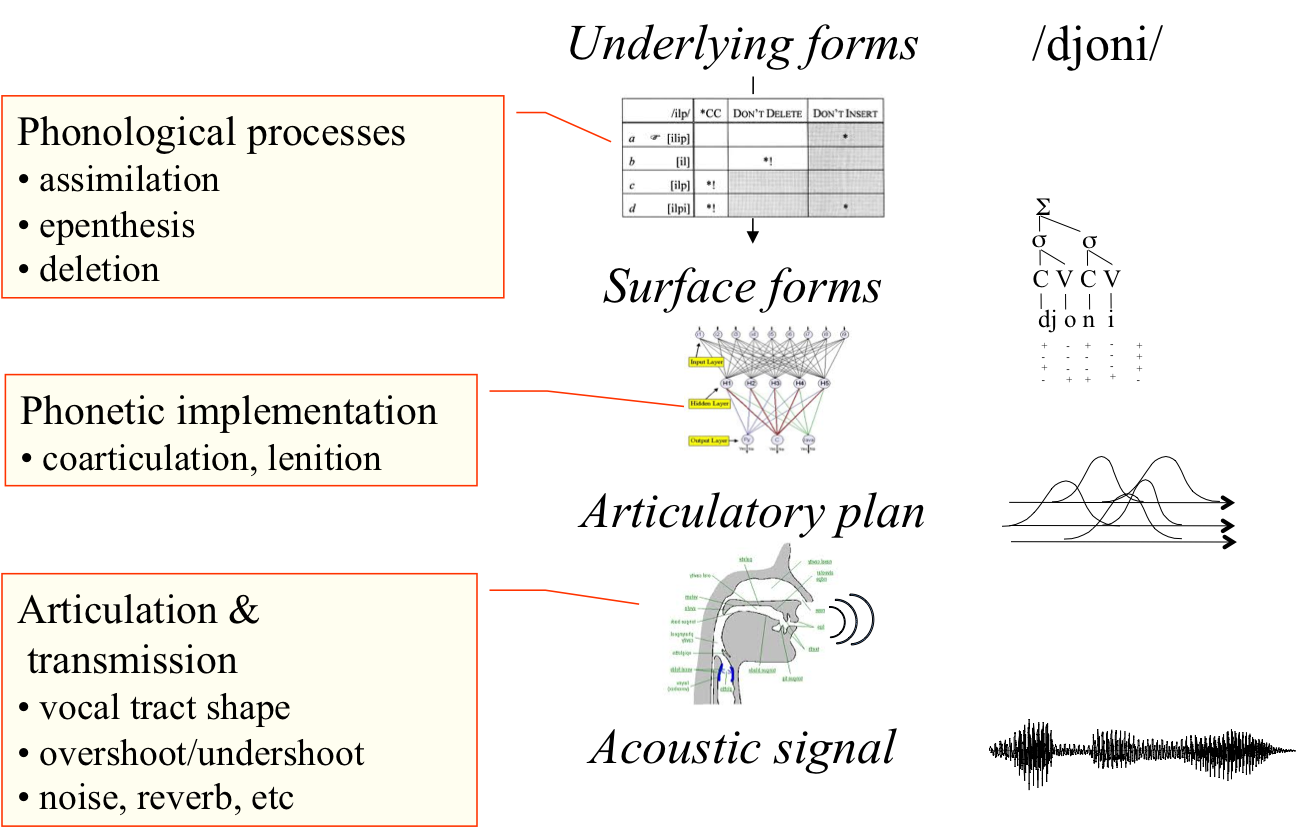
Figure2. Sources of variability for speech sounds
Par conséquent, il existe une absence frappante de correspondance univoque entre les éléments acoustiques observables et les unités linguistiques sous-jacentes. La tâche du nourrisson est d’inverser la chaîne des processus phonologiques, phonétiques et acoustiques, sans connaître les paramètres de ces processus. Concernant l’interdépendance, les différents sous-problèmes d’apprentissage ne peuvent pas être considérés séparément. Par exemple, les algorithmes de regroupement non supervisé utilisent généralement comme données d’entrée un petit nombre de paramètres phonétiques sélectionnés manuellement : fréquence formantique moyenne, durée du phonème, etc. Cela présuppose que les nourrissons savent comment segmenter le flux continu en entités discrètes comme les consonnes ou les voyelles, et quels indices sont pertinents ; ceci est problématique étant donné que la segmentation et la sélection des indices ne sont pas universelles mais dépendent des règles phonologiques de la langue. De même, les algorithmes de segmentation des mots présupposent que la parole est représentée en termes de phonèmes ou de syllabes discrets, qui eux-mêmes dépendent des règles phonologiques. Cependant, les modèles computationnels d’induction de règles phonologiques fonctionnent sous l’hypothèse que les formes des mots sont disponibles, et dépendent donc des deux composantes précédentes. Ces dépendances logiques conduisent naturellement à un paradoxe d’amorçage.
Sous-projets
L’objectif global est de construire un modèle computationnel complet et de le relier à des structures cérébrales spécifiques (voir Figure 3). Pour atteindre cet objectif, nous examinons des questions clés dans des sous-projets menés au sein du groupe ou avec des collaborateurs. Ces sous-projets utilisent une variété de techniques d’apprentissage automatique sur de grandes bases de données de corpus de parole réels (400h de japonais et de néerlandais spontanés), et réalisent des tests empiriques chez les nourrissons humains (0-12 mois) en utilisant des techniques comportementales (mouvements oculaires) ou d’imagerie (EEG haute densité, spectroscopie fonctionnelle dans le proche infrarouge).
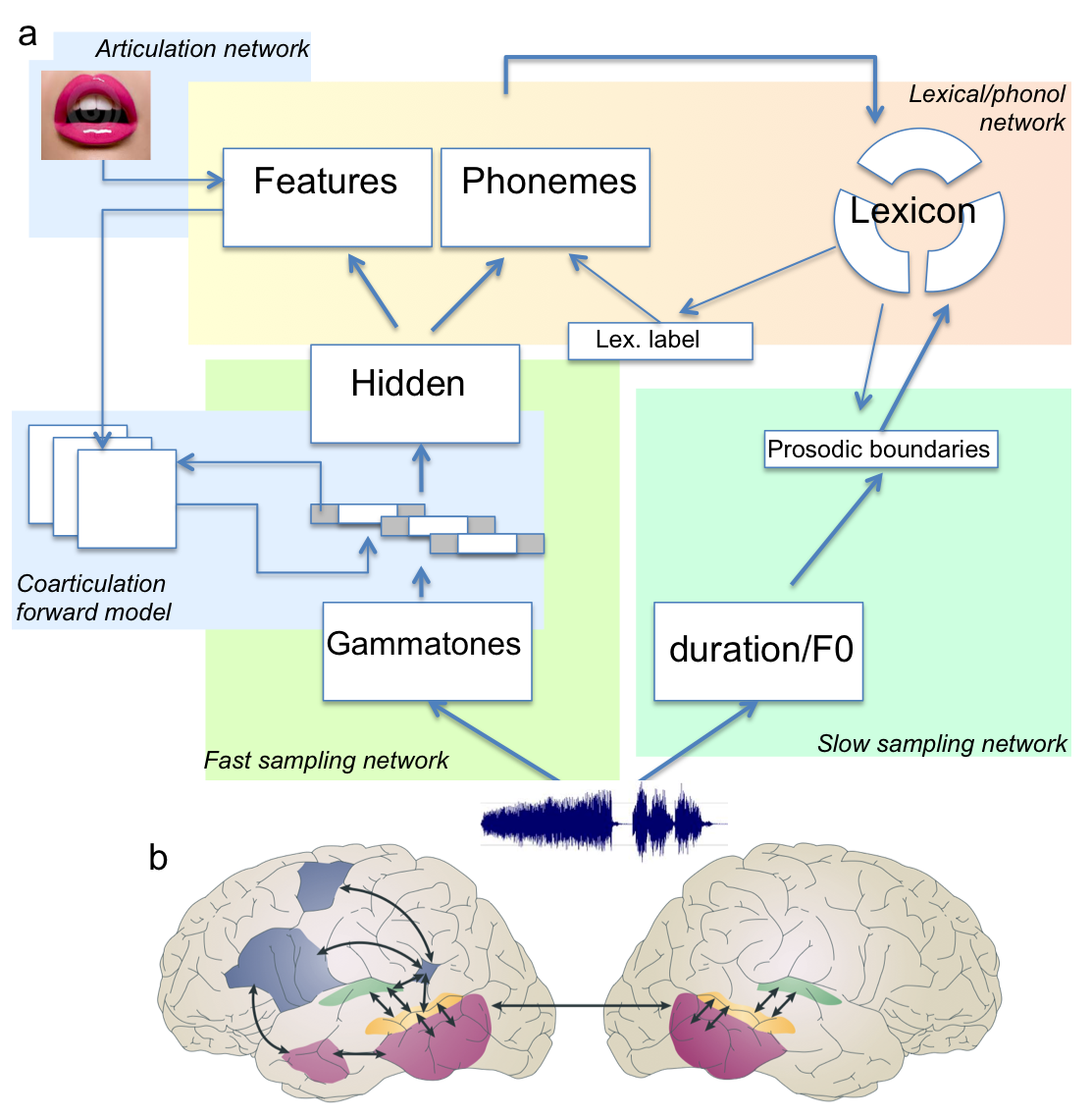
Figure 3. Tentative architecture for a model of early language acquisition. b. Candidate brain regions for the implementation of the model (from Hickock & Poeppel, 2007).
Encodage de la parole
Découvrir automatiquement des unités linguistiques comme les phonèmes à partir de la parole est difficile, en partie parce que la parole est habituellement représentée en termes de vecteurs de caractéristiques locales (par exemple, des coefficients cepstraux ou des caractéristiques auditives calculées sur une fenêtre de 15-25 ms). Les groupes construits sur ce type de caractéristiques correspondront nécessairement à des événements spectro-temporels plutôt locaux. Mais les phonèmes sont produits sous forme de trajectoires articulatoires superposées s’étendant entre 50 et 150 ms, et finissent par être représentés comme des séquences de tels groupes. L’objectif de ce sous-projet est de contourner le problème de cette inadéquation en remplaçant les codes de caractéristiques à grain fin par des codes à grain grossier qui couvrent un fragment plus large du signal de parole. Nous utilisons actuellement des dictionnaires épars et des réseaux de croyance profonds (Hinton, 2007) pour dériver de telles caractéristiques.
Acquérir un protolexique
Traditionnellement, en linguistique, les phonèmes sont définis en termes de paires minimales : /r/ et /l/ sont deux phonèmes distincts en anglais parce que “right” et “light” signifient des choses différentes. Aucune paire de ce type n’existe en japonais, par conséquent, le japonais n’a pas de contraste entre /r/ et /l/. Cela pourrait être utile pour découvrir des catégories phonétiques. Cependant, il semble que les nourrissons ne comprennent pas suffisamment de mots (environ 100 mots à la fin de la première année) pour rendre une telle stratégie possible, étant donné que les paires minimales sont assez rares dans la plupart des langues. Toutefois, la plupart des chercheurs ont négligé la possibilité que les nourrissons puissent reconnaître un grand nombre de formes de mots familières avant de savoir ce que ces mots signifient. L’objectif de ce sous-projet est d’explorer comment un ‘protolexique’ rudimentaire pourrait être construit par le jeune nourrisson (par découverte non supervisée de termes parlés, Brent, 1999), ce qui pourrait l’aider à apprendre les structures phonologiques, même si ce protolexique contient de nombreuses erreurs.
Autres sous-projets
Au fur et à mesure que l’équipe s’agrandit, nous développerons des sous-projets dans certains des domaines suivants : la modélisation inverse de la co-articulation, la normalisation non supervisée du locuteur, la découverte de la structure prosodique (frontières prosodiques et caractéristiques prosodiques), la découverte de classes ou de traits phonologiques, le rôle des interactions enfant-parent, la détection et la modélisation des variations dialectales/sociolectales, le rôle potentiel d’informations sémantiques rudimentaires, l’extraction des mots-outils, et les interactions entre tous ces niveaux. Nous nous intéressons également à l’émergence de la spécialisation cérébrale pour le langage dans la petite enfance ainsi qu’aux corrélats cérébraux des mécanismes computationnels de l’acquisition du langage.
Outils
La partie modélisation de ce projet repose sur :
-
la reconnaissance automatique de la parole (Hidden Markov Models, see Jelinek, 1998; zero ressource speech technologies, e.g. Park & Glass, 2008),
-
les techniques d’apprentissage automatique (clustering, structure discovering, deep belief networks, sparse coding, e.g. Hoyer, 2003, Mohamed et al, 2012),
-
le traitement du signal (modeling of auditory processing in the brain, e.g. Smith & Lewicky, 2006, Pasley et al 2012),
-
les modèles bayésiens (adaptor grammars, voir Johnson & Demuth, 2010: Goldwater et al, 2009).
La partie expérimentale de ce projet repose sur :
-
les techniques d’oculométrie chez les nourrissons (voir Aslin, 2012),
-
les EEG (eg, Dehaene-Lambertz & Gliga, 2004),
-
la spectroscopie fonctionnelle dans le proche infrarouge, fNIRS (voir Minagawa-Kawai, et al 2008; Gervain et al, 2011).
References
Aslin, R. N. (2012). Infant eyes: A window on cognitive development. Infancy, 17, 126-140.
Brent, M. R. (1999). Speech segmentation and word discovery: A computational perspective. TICS, 3, 294-300.
Dehaene-Lambertz, G. & Gliga, T. (2004). Common neural basis for phoneme processing in infants and adults. Journal of Cognitive Neuroscience, 16:1375-87.
Gervain, J., Mehler, J., Werker, J. F., Nelson, C. A., Csibra, G., Lloyd-Fox, S., Shukla, M., and Aslin, R. N. (2011). Near-Infrared Spectroscopy: A Report from the McDonnell Infant Methodology Consortium. Developmental Cognitive Neuroscience, 1, 22-46.
Goldwater, S., Griffiths, T. & Johnson, M. (2009). A Bayesian Framework for Word Segmentation: Exploring the Effects of Context, Cognition 112:1, pp. 21-54.
Hickok, G. & Poeppel, D. (2007). The cortical organization of speech processing. Nat. Rev. Neuroscience 8, 393-402.
Hinton, G.E., (2007). Learning multiple layers of representation. Trends in Cognitive Science, 11(10) :428-434.
Hoyer, P.O. (2003). Modeling receptive fields with non-negative sparse coding. Neurocomputing, 52-54, 547-552.
Jelinek, F. (1998). Statistical Methods of Speech Recognition. Cambridge, Mass: MIT Press.
Johnson, M. & Demuth, K. (2010). Unsupervised phonemic Chinese word segmentation using Adaptor Grammars, Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), pp. 528-536.
Kuhl, P. K. (2004). Early language acquisition: cracking the speech code. Nature Reviews Neuroscience, 5, 831-843.
Minagawa-Kawai, Y., Mori, K., Hebden, J.C., Dupoux, E., (2008). Optical imaging of infants’ neurocognitive development: recent advances and perspectives. Dev Neurobiol 68, 712-728.
Mohamed, A., Dahl, G. E. and Hinton, G. E. (2012). Acoustic Modeling using Deep Belief Networks. IEEE Trans. on Audio, Speech, and Language Processing.
Park, A. and Glass, J. R. (2008). Unsupervised pattern discovery in speech, IEEE T-ASLP, 16(1), pp. 186-197.
Pasley, B.N., David, S.V., Mesgarani, N., Flinker, A., Shamma, S.A, et al. (2012). Reconstructing Speech from Human Auditory Cortex. PLoS Biol 10(1): e1001251.
Vallabha, G. K., McClelland, J. L., Pons, F., Werker, J. & Amano, S. (2007) Unsupervised learning of vowel categories from infant-directed speech, PNAS, 104:33, 13273-13278.
Smith, E. & Lewicki, M. S. (2006). Efficient Auditory Coding, Nature, 439, 978-982.
Tesar, B., & Smolensky, P. (1998). Learnability in Optimality Theory. Linguistic Inquiry 29; 229-268.